
In my last article, I talked about uptime checkers being the bedrock of your monitoring stack. Over the years, I’ve picked up a few tips and tricks that can help you utilize these tools to their fullest. So without further ado, let’s check out some of my favorite ways to use uptime checkers.
Use Keyword Checks
I always prefer using keyword checks over simple HTTP tests. The reason is simple: less false negatives. Almost always, there is some keyword or HTML snippet that should always be on the page, even if it’s as simple as a Terms of Service link or a page title.
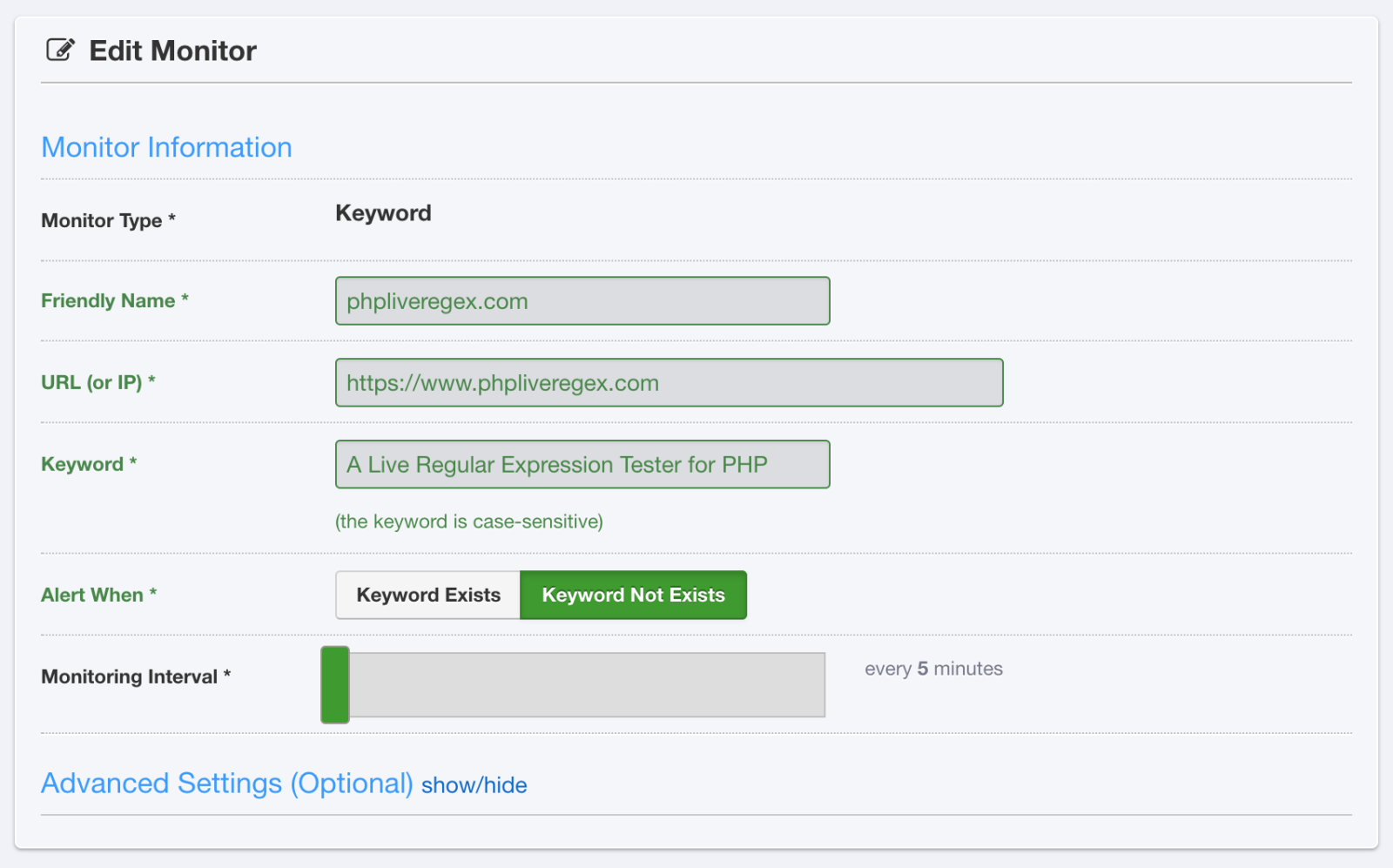
By using keyword checks, you can avoid a whole host of stupid errors that can cause your simple HTTP monitor to stay green when it should be telling you there is a problem. Things I’ve seen in production that keyword checks have identified and alerted me to:
- IIS returning 200 responses when it was showing exception pages
- Elasticsearch indices being broken, causing pages to render no results
- APIs being shipped with bugs and returning incorrect JSON responses
Ideally, all of these things would have been caught in a staging environment or by developers/QA during testing. Sometimes that doesn’t happen and if there’s something wrong in production, it’s always better to know about it.
Monitor All Your Domain Variations
I’d recommend creating a monitor for all variants of your domain. For example, http://, http://www., https:// and https://www.. This can catch a few types of issues:
- DNS misconfiguration
- Reverse proxy misconfiguration
- SSL certificate problems
One issue with this strategy is that these alerts can become a bit noisy if you have a full-scale outage that impacts all the domains. To handle that scenario, you can funnel your alerts into a platform like PagerDuty or OpsGenie and deduplicate or aggregate these alerts. If some of the alerts are less important (for instance, 99% of traffic comes through https://www.), you could always disable alerting on the other domains while still having visibility into their status when you visit your uptime checker.
(Speaking of SSL certificate problems, you can use this free service to monitor your SSL certificate expiration for you and find out about any upcoming certificate expirations before you find out with your uptime checker.)
Monitor 3rd-Party Dependencies
This isn’t something I’d necessarily recommend using extensively… After all, your service provider should be monitoring these heh. However, it can be still be useful in helping you gauge whether a service provider is living up to its SLA or your uptime requirements.
At my last company, we were hit with an outage of a pretty critical reverse geocoding API we were using on one of our mapping pages. The first time this went out, we found out via our CEO… Not good. Setting up an alert on this API let us know that the service was having pretty consistent intermittent outages that were impacting our users and we were able to swap in a replacement that performed much better.
Monitor More Than Just Your Homepage
Finally, you should take advantage of the large number of monitors most services let you make.
- Monitor your public APIs to make sure that your meeting your SLAs.
- Monitor the pages that are most important to your visitors.
- Monitor your customer support pages to ensure those are always up and available.
Your site is much more than just your homepage, so make sure to monitor all of it!
Conclusion
Hopefully, you’ve found some of these tips enlightening and can apply them to the sites your responsible for so you can respond to outages sooner and get those 3 9s of reliability!
Any thoughts? Did I miss something? Send me an email.
Level up your devops skills as fast as you can
Get bi-weekly emails about monitoring and bring your uptime to 99.999%!
I respect your email privacy.